Recitation 2
Today, we will cover more advanced C++ features including standard library containers and object-oriented programming.
Table of contents
Announcements
Office Hours will be held in 26-328 on Tuesday and Thursday from 4-6pm.
Intro to C++ (Part 2)
Memory Management (Revisited)
Last time, we covered the basics of memory management in C++. To help solidify our understanding, we will give a quick recap of the concepts we covered last time.
A program’s memory space is divided into several regions:
- Code region: Contains the program’s instructions
- Data region: Contains global variables
- Stack: Contains local variables and function parameters
- Heap: Contains dynamically allocated memory
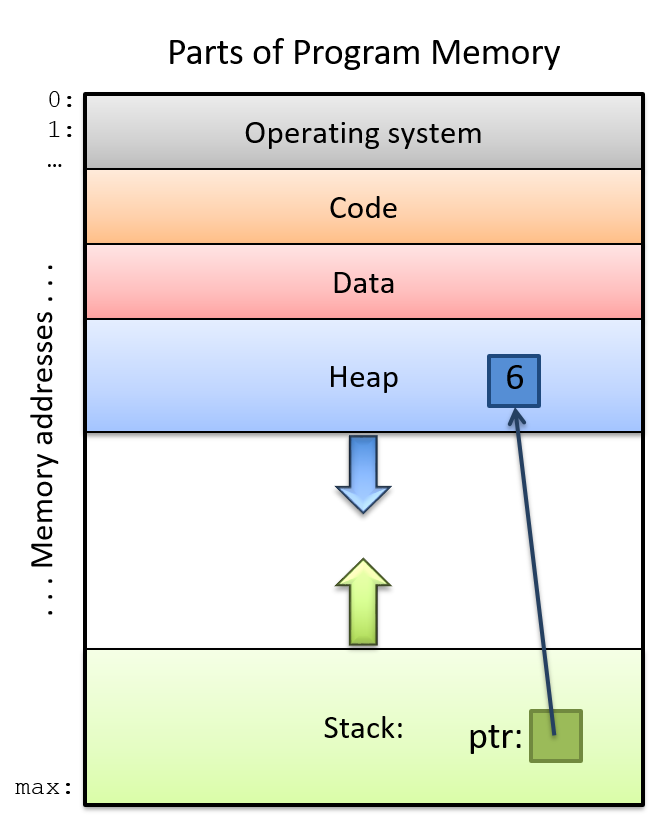
Figure 3 illustrates the parts of a running program’s memory with an example of a pointer variable (int *ptr) on the stack that stores the address of dynamically allocated heap memory (it points to heap memory).
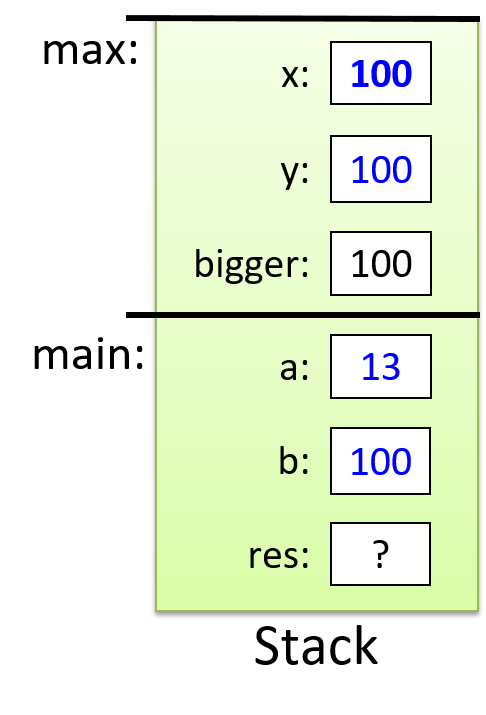
Suppose we have the following function, max, which computes the larger of two integers:
int max(int x, int y) {
int bigger;
bigger = x;
if (y > x) {
bigger = y;
}
return bigger;
}
int main(int argc, char *argv[]) {
int a, b, res;
std::cout << "Enter two integer values: ";
std::cin >> a >> b;
res = max(a, b);
std::cout << "The larger value of " << a << " and " << b << " is " << res << std::endl;
return 0;
}
Last time, we spoke about the execution stack of a program. Whenever a function, such as max, is called, a new stack frame (sometimes called an activation frame or activation record) is created for it. This stack frame contains the local variables and function parameters for the function.
The frame on the top of the stack is the active frame; it represents the function activation that is currently executing, and only its local variables and parameters are in scope. When a function returns, its stack frame is removed from the stack (popped from the top of the stack), leaving the caller’s stack frame on the top of the stack.
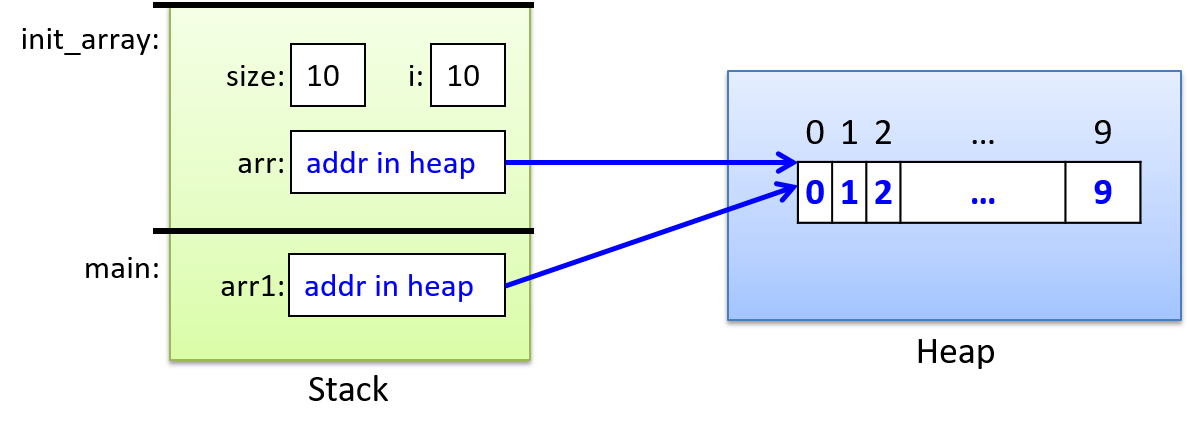
Last recitation, we also spoke about dynamic allocation of memory on the heap. In the example below, we create an array of size 10 on the heap and pass it to the function init_array.
When passing a dynamically allocated array to a function, the pointer variable argument’s value is passed to the function (i.e., the base address of the array in the heap is passed to the function). Thus, when passing either statically declared or dynamically allocated arrays to functions, the parameter gets exactly the same value — the base address of the array in memory.
void init_array(int *arr, int size) {
for (int i = 0; i < size; i++) {
arr[i] = i * i;
}
return arr;
}
int main() {
int size = 10;
int *arr = new int[size];
init_array(size);
delete[] arr;
return 0;
}
Object-Oriented Programming
So far, we’ve been writing our programs in a single file. In your projects, you’ll want to split your code across multiple files. The easiest way to do this is with header files.
A header file has a .hpp extension and contains declarations of functions and classes. Here’s a simple example for a linked list class.
// FILE: linked_list.hpp
#pragma once
class LinkedList {
public:
LinkedList();
~LinkedList();
};
Header files don’t contain implementation details - just declarations.
Here we’ve defined a LinkedList class with a constructor and destructor. The constructor runs when you create an object, and the destructor runs when the object is destroyed.
Now let’s implement these in a source file:
// FILE: linked_list.cpp
#include "linked_list.hpp"
LinkedList::LinkedList() {
// TODO: Implement the constructor
}
LinkedList::~LinkedList() {
// TODO: Implement the destructor
}
Notice how we have the #include directive to include the header file. This is necessary to access the declarations of the class.
Here’s a simple main file:
// FILE: main.cpp
#include "linked_list.hpp"
int main(int argc, char* argv[]) {
LinkedList *list = nullptr;
return 0;
}
Make
So far we’ve only built single-file programs. For multi-file projects, you could compile everything manually:
g++ -o linked_list main.cpp linked_list.cpp
For more sophisticated projects, you will want to use a build system. Let’s look at GNU Make.
In Make, you specify what you want to build and what it depends on. For example, to build the linked_list executable, we need main.cpp and linked_list.cpp.
linked_list: main.cpp linked_list.cpp
g++ -o linked_list main.cpp linked_list.cpp
In larger projects, we want to take advantage of incremental building. This means that we only rebuild the files that have changed. We can do this by specifying object files and then linking them together. Object files are the intermediate files that are produced when we compile a .cpp file.
linked_list: main.o linked_list.o
g++ -o linked_list main.o linked_list.o
main.o: main.cpp
g++ -c main.cpp -o main.o
linked_list.o: linked_list.cpp
g++ -c linked_list.cpp -o linked_list.o
You can imagine that listing out a rule for each object file is tedious. Instead, we can use a wildcard rule to specify a general method to build each object file.
linked_list: main.o linked_list.o
g++ -o linked_list main.o linked_list.o
%.o: %.cpp
g++ -c $< -o $@
Here % is a wildcard that matches any string of characters (in the same directory as the Makefile). Make also has metavariables like $@ which expands to the target of the rule and $< which expands to the first dependency. There is also a metavariable which expands to all the dependencies of the rule, $^.
We can build C++ files with optimization flags by specifying the -O3 flag, which tells the compiler to optimize the code for performance.
CXXFLAGS += -O3
linked_list: main.o linked_list.o
$(CXX) $(CXXFLAGS) -o linked_list main.o linked_list.o
%.o: %.cpp
$(CXX) $(CXXFLAGS) -c $< -o $@
Member Variables
In a class, we can define member variables. Member variables are variables that are associated with an object of the class. They are declared in the class definition and are accessible to all the functions in the class.
// FILE: linked_list.hpp
class LinkedList {
public:
int value;
LinkedList* next;
LinkedList();
~LinkedList();
};
Here we have two member variables: value (an integer) and next (a pointer to another LinkedList).
The public keyword means these variables are accessible from anywhere in the program. Usually you want member variables to be private so only the class functions can access them.
// FILE: linked_list.hpp
class LinkedList {
private:
int value;
LinkedList* next;
public:
LinkedList(int value);
~LinkedList();
};
Now let’s initialize the member variables in the constructor:
// FILE: linked_list.cpp
LinkedList::LinkedList(int value) : value(value), next(nullptr) { }
This syntax initializes member variables before the constructor body runs. It’s equivalent to:
LinkedList::LinkedList(int value) {
value = value;
next = nullptr;
}
We prefer to use the first syntax because it runs before the constructor body is executed.
Member Functions
Member functions are functions that are associated with an object of the class. They can access and modify the member variables of the class.
// FILE: linked_list.hpp
class LinkedList {
private:
int value;
LinkedList* next;
public:
LinkedList(int value);
~LinkedList();
// Member functions
int getValue() const;
void setValue(int value);
LinkedList* getNext() const;
void setNext(LinkedList* next);
void print() const;
};
// FILE: linked_list.cpp
int LinkedList::getValue() const {
return value;
}
void LinkedList::setValue(int value) {
this->value = value;
}
LinkedList* LinkedList::getNext() const {
return next;
}
void LinkedList::setNext(LinkedList* next) {
this->next = next;
}
void LinkedList::print() const {
std::cout << "Value: " << value << std::endl;
}
Notice the const keyword after the function name. This means that the function does not modify the object’s state. The this pointer refers to the current object.
Overloading
Function overloading allows you to define multiple functions with the same name but different parameters. The compiler chooses which function to call based on the arguments provided.
// FILE: linked_list.hpp
class LinkedList {
private:
int value;
LinkedList* next;
public:
LinkedList(int value);
LinkedList(); // Default constructor
~LinkedList();
// Overloaded functions
void add(int value);
void add(int value, int position);
void print() const;
void print(const std::string& prefix) const;
// Operator overloading
LinkedList& operator+(int value); // Overload + operator
LinkedList& operator+=(int value); // Overload += operator
};
// FILE: linked_list.cpp
LinkedList::LinkedList() : value(0), next(nullptr) { }
void LinkedList::add(int value) {
// Add to the end
LinkedList* current = this;
while (current->next != nullptr) {
current = current->next;
}
current->next = new LinkedList(value);
}
void LinkedList::add(int value, int position) {
// Add at specific position
LinkedList* current = this;
for (int i = 0; i < position && current->next != nullptr; i++) {
current = current->next;
}
LinkedList* newNode = new LinkedList(value);
newNode->next = current->next;
current->next = newNode;
}
void LinkedList::print() const {
std::cout << "Value: " << value;
if (next != nullptr) {
std::cout << " -> ";
next->print();
} else {
std::cout << std::endl;
}
}
void LinkedList::print(const std::string& prefix) const {
std::cout << prefix << "Value: " << value;
if (next != nullptr) {
std::cout << " -> ";
next->print(prefix);
} else {
std::cout << std::endl;
}
}
// Operator overloading implementations
LinkedList& LinkedList::operator+(int value) {
add(value); // Call the existing add function
return *this; // Return reference to current object
}
LinkedList& LinkedList::operator+=(int value) {
add(value); // Call the existing add function
return *this; // Return reference to current object
}
// FILE: main.cpp
int main(int argc, char *argv[]) {
LinkedList list(1);
// Using overloaded + operator
list + 2 + 3; // Equivalent to list.add(2).add(3)
// Using overloaded += operator
list += 4; // Equivalent to list.add(4)
list.print(); // Output: Value: 1 -> Value: 2 -> Value: 3 -> Value: 4
return 0;
}
Destructors
A destructor is a special member function that is called when an object is destroyed. It’s used to clean up resources, especially dynamically allocated memory.
// FILE: linked_list.hpp
class LinkedList {
private:
int value;
LinkedList* next;
public:
LinkedList(int value);
~LinkedList();
// Other methods...
};
// FILE: linked_list.cpp
LinkedList::~LinkedList() {
if (next != nullptr) {
delete next;
}
}
The destructor is called automatically when the object goes out of scope. For dynamically allocated objects, the destructor is called when you use delete. If you don’t define a destructor, the compiler provides a default one, but the default destructor does NOT free dynamically allocated memory.
Example usage:
int main() {
LinkedList* list = new LinkedList(1);
list->add(2);
list->add(3);
list->print();
delete list;
return 0;
}
Inheritance
Inheritance allows a class to inherit member variables and methods from another class. In C++, this enables code reuse and polymorphism through virtual functions.
In C++, the most important concept to understand when it comes to inheritance is the difference between early binding and late binding.
Early binding occurs when the function call is resolved at compile time, where the compiler knows exactly which function to call based on the variable’s declared type. Late binding occurs when the function call is resolved at runtime, where the actual function called depends on the object’s real type, not its declared type.
Late binding is implemented through a virtual table (vtable). A vtable is a runtime data structure that is associated with each object that has virtual functions. The vtable is used to store the addresses of the functions that are overridden by the derived class.
Virtual functions enable late binding, allowing derived classes to override base class functions, and the correct version is called based on the actual object type.
// FILE: list.hpp
class List {
public:
virtual void add(int value) = 0; // Pure virtual function
virtual void print() const = 0; // Pure virtual function
virtual int size() const = 0; // Pure virtual function
virtual ~List() = default; // Virtual destructor
};
class LinkedList : public List {
private:
int value;
LinkedList* next;
public:
LinkedList(int v) : value(v), next(nullptr) {}
void add(int value) override {
LinkedList* current = this;
while (current->next != nullptr) {
current = current->next;
}
current->next = new LinkedList(value);
}
void print() const override {
std::cout << value;
if (next != nullptr) {
std::cout << " -> ";
next->print();
} else {
std::cout << std::endl;
}
}
int size() const override {
int count = 1;
LinkedList* current = next;
while (current != nullptr) {
count++;
current = current->next;
}
return count;
}
~LinkedList() {
if (next != nullptr) {
delete next;
}
}
};
class VectorList : public List {
private:
std::vector<int> data;
public:
VectorList(int initialValue) {
data.push_back(initialValue);
}
void add(int value) override {
data.push_back(value);
}
void print() const override {
for (size_t i = 0; i < data.size(); i++) {
std::cout << data[i];
if (i < data.size() - 1) {
std::cout << " -> ";
}
}
std::cout << std::endl;
}
int size() const override {
return data.size();
}
};
Key concepts: The virtual keyword enables late binding (dynamic dispatch), while = 0 makes a function pure virtual (abstract). The override keyword ensures you’re actually overriding a virtual function, and virtual destructors ensure proper cleanup in inheritance hierarchies. Both classes implement the same interface but with different data structures.
Here is an example of early binding and late binding.
// Without virtual (Early Binding)
class Base {
public:
void print() { std::cout << "Base" << std::endl; }
};
class Derived : public Base {
public:
void print() { std::cout << "Derived" << std::endl; }
};
// With virtual (Late Binding)
class BaseVirtual {
public:
virtual void print() { std::cout << "BaseVirtual" << std::endl; }
};
class DerivedVirtual : public BaseVirtual {
public:
void print() override { std::cout << "DerivedVirtual" << std::endl; }
};
int main() {
Base* basePtr = new Derived();
basePtr->print();
BaseVirtual* virtualPtr = new DerivedVirtual();
virtualPtr->print();
delete basePtr;
delete virtualPtr;
return 0;
}
Example usage:
int main() {
List* lists[] = {
new LinkedList(1),
new VectorList(1)
};
for (int i = 2; i <= 5; i++) {
lists[0]->add(i);
lists[1]->add(i);
}
for (int i = 0; i < 2; i++) {
std::cout << "List " << (i+1) << ": ";
lists[i]->print();
std::cout << "Size: " << lists[i]->size() << std::endl;
delete lists[i];
}
return 0;
}
Containers
Smart Pointers
Smart pointers automatically manage memory, preventing memory leaks and making code safer. The two important ones are std::unique_ptr and std::shared_ptr. There’s also std::weak_ptr which we won’t cover.
std::unique_ptr is an exclusive ownership pointer. It automatically deletes the object when it goes out of scope, and cannot be copied, only moved (by using std::move).
#include <memory>
#include <iostream>
class Node {
public:
int value;
std::unique_ptr<Node> next;
Node(int v) : value(v), next(nullptr) {}
void print() const {
std::cout << value;
if (next) {
std::cout << " -> ";
next->print();
} else {
std::cout << std::endl;
}
}
};
int main() {
auto head = std::make_unique<Node>(1);
head->next = std::make_unique<Node>(2);
head->next->next = std::make_unique<Node>(3);
head->print();
return 0;
}
std::shared_ptr: std::shared_ptr is a shared ownership pointer. It automatically deletes the object when the last reference is destroyed. std::shared_ptr implements a form of garbage collection, which we will cover extensively later in this course, called reference counting.
This mechanism is not as popular for language implementations, which typically use tracing garbage collection, but it is used in many places such as in C++, the Linux kernel, distributed systems, and more.
#include <memory>
#include <vector>
int main() {
std::vector<std::shared_ptr<Node>> nodes;
auto node1 = std::make_shared<Node>(10);
auto node2 = std::make_shared<Node>(20);
nodes.push_back(node1);
nodes.push_back(node2);
return 0;
}
Vectors
std::vector is a dynamic array that automatically manages its size. It’s the most commonly used container in C++.
#include <vector>
#include <iostream>
int main() {
std::vector<int> numbers;
numbers.push_back(10);
numbers.push_back(20);
numbers.push_back(30);
std::cout << "First element: " << numbers[0] << std::endl;
std::cout << "Size: " << numbers.size() << std::endl;
for (size_t i = 0; i < numbers.size(); i++) {
std::cout << numbers[i] << " ";
}
std::cout << std::endl;
for (int& num : numbers) {
num += 1;
std::cout << num << " ";
}
std::cout << std::endl;
numbers.pop_back();
if (!numbers.empty()) {
std::cout << "Vector is not empty" << std::endl;
}
return 0;
}
Double Ended Queues
std::deque (double-ended queue) allows efficient insertion and deletion at both ends. I’m not sure how it’s implemented under the hood, but it’s efficient and useful.
#include <deque>
#include <iostream>
int main() {
std::deque<int> dq;
dq.push_front(1);
dq.push_back(2);
dq.push_front(0);
dq.push_back(3);
std::cout << "Front: " << dq.front() << std::endl;
std::cout << "Back: " << dq.back() << std::endl;
dq.pop_front();
dq.pop_back();
for (int val : dq) {
std::cout << val << " ";
}
std::cout << std::endl;
return 0;
}
Maps
std::map is an associative container that stores key-value pairs in sorted order. It’s implemented as a balanced binary search tree.
#include <map>
#include <string>
#include <iostream>
int main() {
std::map<std::string, int> ages;
ages["Alice"] = 25;
ages["Bob"] = 30;
ages["Charlie"] = 35;
ages.insert(std::make_pair("David", 28));
std::cout << "Alice's age: " << ages["Alice"] << std::endl;
if (ages.find("Eve") != ages.end()) {
std::cout << "Eve found!" << std::endl;
} else {
std::cout << "Eve not found" << std::endl;
}
for (const auto& pair : ages) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
ages["Alice"] = 26;
ages.erase("Charlie");
std::cout << "Number of people: " << ages.size() << std::endl;
return 0;
}
There is also std::unordered_map which is an unordered map that is implemented as a hash table. It has a better amortized time complexity than std::map; however, it does not maintain the sorted order of the keys.
Conclusion
In the next recitation, we’ll cover writing a toy lexer/parser which should help you get started for phase 1.
Here are some C++ resources to explore on your own: